
Ideology Mapping and Mincing Decentralized Identity
Mapping & Mincing the Ideology of Decentralized Identity
tl;dr
I was asked to introduce “decentralized identity qua [ideological] movement” at #IIW30 as part of Karyl Fowler’s “Intro to SSI” session and it spurred what might generously be called a productive moment of reflection on whether I’m adding to or subtracting from an ideological fog that could well serve as a smokescreen for profiteering. I tried to map decentralized identity as a confluence of three perhaps unrelated agendas that contingently agree on a shared technological toolkit. I found the exercise useful and generative for myself, although I can’t say the resulting excursus was particularly illuminating for the many IIW first-timers attending the session, some of whom rightly asked wtf I was on about in post-presentation Q&A. Afterwards, posting the diagram to twitter, Philip Sheldrake also asked wtf I was on about, but in the key of ideological critique, so I did my best to answer fairly but essentially off the cuff; these remarks are appended as well, as convincing as they may or may not be as answers to Philip’s questions. Since Kaliya Young put out a rallying cry at another panel of the same conference to bring back blogging, I thought I should convert the exercise into an old-fashioned, early-00s style blog reflection. Luckily, I already had this blog set up thanks to indieweb enthusiast Infominer! All photos by Barbara Kruger except the second, by Laura Spencer.
The backstory to this excursus is that I have been following lots of adjacent but essentially unrelated (and in many cases older) currents in European data activism lately, trying to deepen and widen my familiarity with other currents in technological thinking with similar goals to my own. Now that I work full-time for a for-profit, mostly closed-source software company that builds decentralized identity products, I think a lot about what the end-game is, and where the incentives of a company looking to create a sustainable, defensible niche for itself might diverge from the incentives of some amorphous agenda held by the “big tent” of deentralized identity technologists, which includes lots of non-profit driven work being done by governments and open-source communities. In particular, the European Commission’s “Next Generation Internet” projects has just been killing it in the crates lately, funding stop-gaps and bridges to make profit-driven Web3.0 work more useful to the public good.
As for the excursus itself, Karyl Fowler, CEO of Transmute Industries, asked me to co-present an “Introduction to SSI,” filling in for my old boss Heather Vescent at the Purple Tornado, who had lead the session at #IIW29. As a way of dividing the topic in two, Karyl presented SSI as a technology, asking me to present it as a movement. Having long participated in the community as a freelance/free-range thinker, this made sense: my engagements with decentralized identity unmoored to any business interests had left a trail of manifestos and attempts to bridge public-good thinking and decentralized identity tech. Rather than defer to the spokespersons or dogmas within SSI that are easily enough googled and refered to by all the introductory texts linked to in the slide deck’s bibliography, I thought instead it might be fun to map the fuzzy boundaries and influences of the widest possible ideological snapshot.
To this end, I wanted to map it out partly to inspire and educate newcomers to the space (the intended audience of the presentation, of course), but also for myself, to stay honest to what pushed me to work in this space to begin with. Recently, Women In Identity published a short but potent piece co-written by two thinkers far more qualified than me to judge the effectiveness of data policy and business practice, Mattr’s Emily Fry and privacy lawyer and policy advocate Elizabeth Reineris. The piece frankly described how the social good of data portability was better served by pro-active regulatory change and legislation than by swapping one for-profit tech business model for another, which struck me as an entirely reasonable interpretation of recent events. Having recently been reading up on lots of data rights activism (MyData in particular) and having recently applied to a European Commision-funded grant program to directly support infrastructure for pragmatic data portability, I took issue with the either/or framing, however, since it allows a vocal minority within the decentralized community to speak for the whole and holds that minority’s marketing claims against the whole community. I tried to resolve the apparent contradiction, because:
- I also think technology alone will not save the little guy from market forces,
- I also prefer regulatory reform to private investment as a seawall against privacy harms, and
- I don’t support private investment that I believe will hinder (or even detract from the urgency of) forces pushing for that reform.
But in the week between that exchange and IIW30, I got to wondering– have some who speak on behalf of decentralized identity promised a market-driven solution to a societal problem? (It’s worth noting an) In many cases, it certainly has, but I would like to believe in that bigger tent, in which decentralized identity (as a business model, and as a set of technologies both private and public, open- and closed-source) can lock open the infrastructure private interests build in such a way that allows for other uses in the public good. If profiteers succeed in shrinking that tent enough to make my belief look naïve or deluded, I’m calling it quits and looking for work elsewhere. In one form or another, this has been my personal investment in the “movement” which decentralized identity (and to a greater degree, that subset of the community that prefers the term “self-sovereign identity” for various reasons), which I have been vocal enough about that Karyl asked me to present that portion of her introduction to the topic.
In any case, here is what I came up with in (full disclosure) 30 minutes of spitballing spread out across three days:
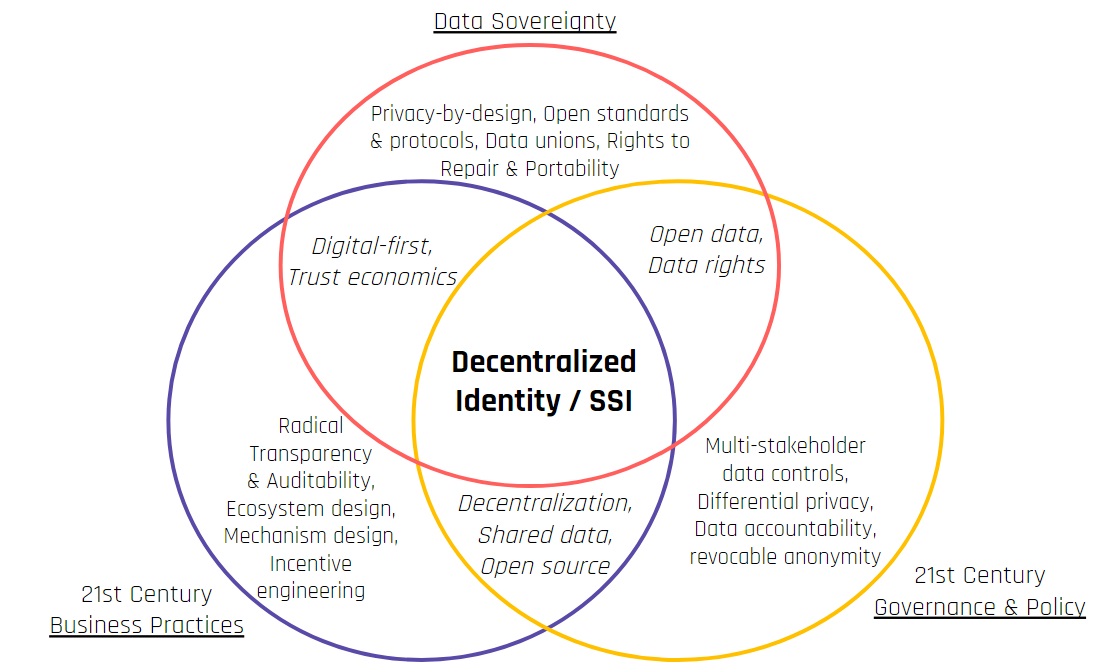
As is usually the case with pitchdeckery, I had to present this tentative map to a room full of guinea pigs and gets some flack about it to fine-tune it in 3 or 4 ways to arrive at the version I’m posting above. But I always wanted to post some further clarifications and challenges that came via Twitter from the Akasha Foundation's resident techno-solutionism skeptic Sheldrake.
.jpg?raw=true)
Trust Economics
DLT tech is only one form taken by trust economics more generally, and definitely what Christopher Allen calls “trustless economics” falls under this category. For further reading on the LESS/Trustless divide within decentralized identity thinking, see Phil Windley’s excellent blog post on the subject. There, Windley lays out Christopher Allen’s and Tim Bouma’s core concepts for a wider audience. I would also clarify that in both Allen’s and Bouma’s original writings on the subject, “trustless” does not refer primarily to real-world trust but rather to cryptographic trust, applying to information businesses an analogy to “zero trust” thinking in cybersecurity. There, “trustless” refers to a move away from reliance on “security perimeters” wide or narrow, opting instead for an “always verify” approach to data and self-certifying/proving identifiers.
But to further complicate this dogpile of domain-specific usages of the term “trust,” I would define “trust economics” for my purposes here as the analysis of the economic role played by not just real-world trust, but also business trust (i.e., liability and risk), as well as technological/informational trust (see above). I am at best an armchair economist, but I would like to think that macroeconomics can actually be a fruitful homebase for interdisciplinary analyses, and this is one such analysis. In my view, trust economics draws from many new ways of protecting data rights and new ways of building platform/ecosystem business models, whether aligned more with L.E.S.S., with for-profit businesses, or with more anonymous/non-state-based economic projects like the Idena network.
.jpg?raw=true)
Sam Smith has written about the “trust tax” in his original meta-platform essay, as the co-founder of Spherity, Carsten Stöcker, in a co-written article of speculative trust economics. The search for alternatives to the “trust tax” whereby the corporation is the only monetizer of trust and guarantor of business trust. To my linking Sam’s article, Philip responded, "Sam's piece is partly predicated on the cost of needing to trust each other historically ("trust tax"). In seeking to minimise those costs, one seeks to need less trust. I think this misses the point of trust economics: companies “trust” each other based on a mix of liability, historically-based predictions, relationships bound by contracts, and actuary calculations of risk, and relying more on one mechanism and less on another does not lower the world’s total supply for trust in zero-sum terms! Trust economics is a kind of double-entry accounting, tracking how trust changes forms and metrics. If there is a zero-sum game at all, it is that for-profit corporations fundamentally trust no one but themselves by nature, and hedge in one way or the other any risks they take in trusting others!
All of this is to say that trust economics, like economics generally, is not a very gay science: approaching issues of trust across different domains from an economic perspective can (and should) drain any warm-and-fuzzy feelings from the term. It will, I hope, be a corrective to the tendency in identity marketing towards what Tim Bouma has called “trustwashing”, whereby technological or legal assurance can be offered as a substitute for actual faith in institutions or businesses under the vague term of “trust”. I know some identity and data technologists (like Paul Knowles of the Human Colossus Foundation) would gladly see this over-used term put to rest, but perhaps my academic background inclines me to flogging the horse until it is way too dead to be of any use to the marketing department.
.jpg?raw=true)
What is the fate of the intersubjective and the collective under a regime of “personal data”?
This is one question where I feel I could never satisfy Philip, whose own writings on identity often focus on this fundamental problem. Profit-driven information technology is generally at the very bleeding edge of capitalism’s perennial imperative to atomize and render all human activity subject to contract, [intellectual property] ownership, and individual liability. If we interpret GDPR’s definition of “personal” data too literally or simplistically, we risk uncritically furthering this aim and making our digital lives even more atomized and cut off from community and civic virtue than our physical ones. I think I share with Akasha the hope that alternatives exist to that! I also share with many the hope that GDPR and data law generally can evolve in more collective and community-supporting directions. I’ll return to that in a moment.
.jpg?raw=true)
But before tackling that more general question about legal frameworks, I can address the more properly ideological qualm about “sovereignty.” I actually use the term quite rarly except in the phrase “data sovereignty,” because this compound includes collective and communitarian forms of sovereignty. Coming from the far left where sovereignty means something very different than it does in mainstream American political usage, I am particularly interested in the tendency to establish data ownership by the Commons, whether defined geographically or internationally. In fact, my first contribution to the decentralized identity community was co-authoring (scribing and editing, really) an RWoT paper on the role of identity technology in the data commons co-authored by Adrian Gropper, who is, years later, still tirelessly arguing for the work of bottoms-up governance and self-selecting communities as the most viable unit of data sovereignty, most recently in the context of Covid mitigation techniques.
Back to terminology, I have personally started to move away from the term “self-sovereignty” because I feel that rhetoric (with its open debts to cyberlibertarianism) too often undervalues communities and collective actors not motivated by profit, and caricatures government and civil society as either nuisances or badly-run corporations. Outside the United States, these echoes and resonances more seriously impede civil society’s and the public sector’s interest in decentralized identity technologies. I avoid using the term “SSI” primarily because the aura of being a [cyberlibertarian] North American export makes decentralized identity less attractive or useful as a tool in European or Global South efforts towards data sovereignty, full stop. If decentralized identity does nothing more than further entrench North American techno-colonialism, that would be another sign it’s time to cash in my chips and go back to painting houses for a living, or teaching languages and literary theory.
.jpg?raw=true)
Are data unions collectively and organically governed enough to be any safer for our data than corporations and the state?
Forgive the hysterics, but I can only get defensive at the implication that unions are bad for community, an assertion which is anathema to my personal politcal ideology. My grandfather worked his whole adult life as a union accountant in Argentina, and never abandoned his public support for his small-farmer collective even during the multiple periods of his life where it was quite literally dangerous to align oneself publically with the union movement. As we joke in Argentina, it was only a “Cold War” in the lucky countries; it got pretty hot where my parents lived when I was born.
I’ll be blunt: unions can be corrupt, they can be centralizing forces, and they can collaborate with other centralizing (or tyrannical) forces, and often have under every form of capitalism and capitalism-alternative yet seen. They are imperfect institutions for pooling the power of workers against capital, and may not be much better, on average, than churches or countries or corporations. But neither labor unions nor data unions can be accused of being inherently centralizing without caricaturing the breadth and variety of theory and praxis grouped under the umbrella of unions as a social form. I will die on this hill, although I’d rather not have to (and it certainly influenced my choice to move to Europe).
.jpg?raw=true)
I am no expert on data unions, but I support lots of the writing and thinking about data collectives and unions coming out the MyData, Me2B Alliance, and Radical Exchange communities and elsewhere. It is an emerging legal and social form that I hope comes into more focus in theory and practice in the coming years. I don’t think the identity tech community can afford to leave this thinking out of the “big tent” of decentralized identity. I sincerely hope that as the Trust-over-IP Foundation is built out and takes on a more international focus, these kinds of sense-making can be incorporated substantially in its mission and the scope of its discussions about roles and rights. Until now, the Sovrin foundation has been pretty good about keeping sovereignty, accessibility, and equity in scope, so I have every reason to believe the new venture will as well.
More generally, though, I guess the process of writing this essay has made clear to me that I need to invest more time in not just studying the efforts of others but actually putting my shoulder to the wheel of making data unions a thing worth having faith in. Live better, compute union!
.jpg?raw=true)
Every time I hear the word “decentralization” I reach for my checkbook
I couldn’t agree more, and I love the article in question, but I think we do Nathan Schneider’s analysis a disservice by using it as an acid bath with which to dismiss any and all interest in decentralization as hypocritical or bad-faith smokescreening of ulterior motives. Paradoxically, I think the calls to decentralize (or re-decentralize) the internet are both legitimate and unrealistic, worthwhile and impossible to definitively scope or measure.
I would rather use Schneider’s analysis as a yardstick against which to measure individual projects of decentralization (and the business models or policy changes they are used to justify). Setting no goal more specific than “decentralizing” an isolated aspect of the stack or the economy is a recipe for superficial coalitions and disappointing outcomes, with that I completely agree. In Schneider’s own words, his “evidence …across several fields suggests that processes of decentralization in one part of a system seem to enable centralization in another,” and no one passionately working towards decentralized identity I know would be so naïve as to claim otherwise.
.jpg?raw=true)
For instance, much work to create a more decentralized web stack leads to a short-term reliance on contemporary cloud infrastructure in many cases, which is clearly trading in the “centralization” of DNS and TCP/IP for a far more geopolitically and ideologically dangerous centralization, at least in the short-term. But organizations like NextCloud and HoloChain have long maintained active ties to the decentralized identity community, and I have every hope that, just as decentralized identity may be able to ween itself off of blockchains and distributed ledger technologies altogether with advances such as the KERI protocol, so too might a less mercenary model of the cloud computing arise in the coming years.
As for how effectively we are decentralizing anything and what other forms of centralization we might play into, the decentralized identity community regularly and heatedly debates this issue. Sometimes these debates devolve into a macho ritual we self-effacingly call “cagematches” (usually at in-person conferences, between old friends), while at other times these debates are channeled into collaborative thinking and writing like that captured in this essay. Jolocom founder Joachim Lohkamp in particular has consistently pushed for this debate to be foregrounded and not deferred or sidelined. He’s pushed for a rubric that might scaffold and structure decision-making about decentralization (and recentralization) at different layers of the stack to be included in the DID core specification, such that the debate could inform the process of standardization and shine a light on recentralizations created along the way. I do not sit on the Worldwide Web Consortium committee that is editing this rubric, but I personally welcome its inclusion in the specification and the foregrounding of these criteria.
.jpg?raw=true)
Trust Triangles are a registered trademark of SSI Corp, LLC
This question struck me as a little disingenuous, since I did not refer to the issuer/holder/verifier triangle anywhere in my diagram, nor anywhere in the technology portion of the presentation either. Since the most widely-disseminated introductions to SSI come from an overtly business-friendly perspective (with governance, policy, and social-good perspectives gestured at but rarely delved into), this has been slipped in as if it were an ideological foundation of decentralized identity or practice, when in fact it is simply the foundation of one business model for decentralized identity. What’s more, it is not even a particularly universal business model– many others currently being funded and subsidizing infrastructural investments for the others (for instance, those dealing only with verified identities but not credentialing, or privacy-preserving big data analytics) are not much illuminated by the triangular model. The familiar triangle would be more accurate described as the basis for credential-based verified information dataflows; even calling it a “trust triangle” seems to me needlessly confusing for all the reasons mentioned above that risk turning “trust” into a weasel-word.
.jpg?raw=true)
I am personally not a huge fan of the issuer/holder/verifier triangle as an explanatory device outside of very specific business contexts. It is most useful when explaining decentralized identity’s most common models for access tokens and reusable credentials by contradistinction from centralized and/or federated identity models in today’s identity and access management practice. After all, the three terms and their relations are canonical and central to the business model of traditional IAM, a multi-billion dollar subindustry within software with its own bibliography and dedicated MBA programs.
The “foundational triangle” is a schematization of relations of power into business relationships that can be rigidified by contracts, just as Philip insinuates. This model is great for building a business model, but should ot be backfilled into the ideological underpinnings or social analysis of the technology’s broader utility and effects. For that, the non-profit and academic work on online harms (and harm reduction) are a better starting point than marketing materials and business-plan pitch decks uploaded to linkedin for the perusal of venture capitalists.
Conclusion
In summary, the answer to all 5 questions is this: there is a better and a worse way to do/conceive/build the general term addressed. These questions all point to open questions and fissures along which today’s decentralized identity community disagrees, debates and competes. All of these are, to put it bluntly, dangers to the net-positive outcome that we all have to believe in to keep working in this emerging field– if the wrong decisions are made on any of these fives fronts, this could all turn out to be business as usual, moving fast, breaking things, and eating the [communities of] the world. Distrust anyone who hand-waves away any of the 5 and offers silver bullets and miracle cures, particularly if they also happen to be selling a product! These are all hard problems and ongoing research topics. If this were easy it wouldn’t be worth doing.